Kpler, la data intelligence pour les matières premières
mardi 21 avril 2020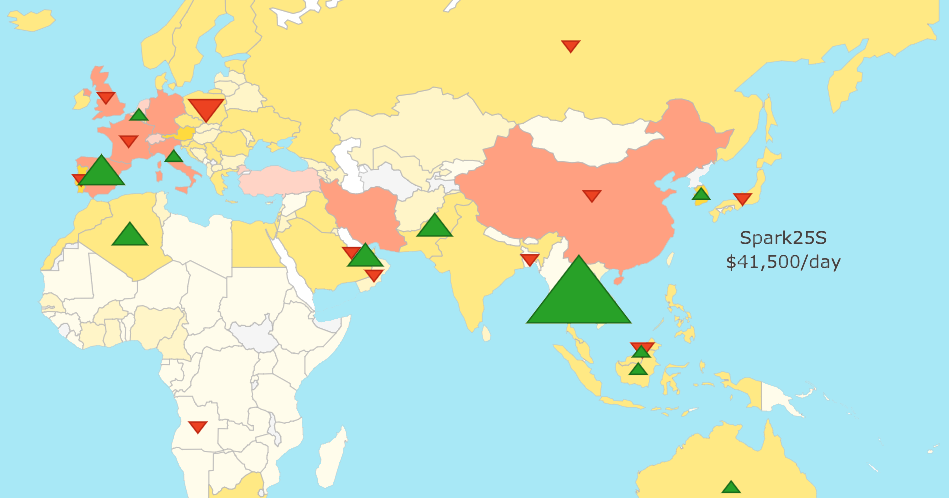
Fondée en 2014, Kpler est une entreprise de Data Intelligence qui développe des solutions de transparence dans le domaine des matières premières, par exemple le butane ou propane (LPG), le gaz naturel (LNG), d’autres produits raffinés et dérivés du pétrole, les minerais, etc. Grâce à une méthodologie et des technologies éprouvées, Kpler collecte, traite et agrège des données brutes provenant de centaines de sources.
Kpler délivre ainsi à ses clients une information à forte valeur ajoutée en combinant ces données avec l’utilisation d’algorithmes de déduction (machine learning, règles complexes, recherche opérationnelle) et une expertise métier, leur permettant d’analyser les flux mondiaux de matières premières en temps réel via des indications sur les flux d’imports/exports, le stockage à terre et en mer, les changements de structure dans les marchés physiques, etc.
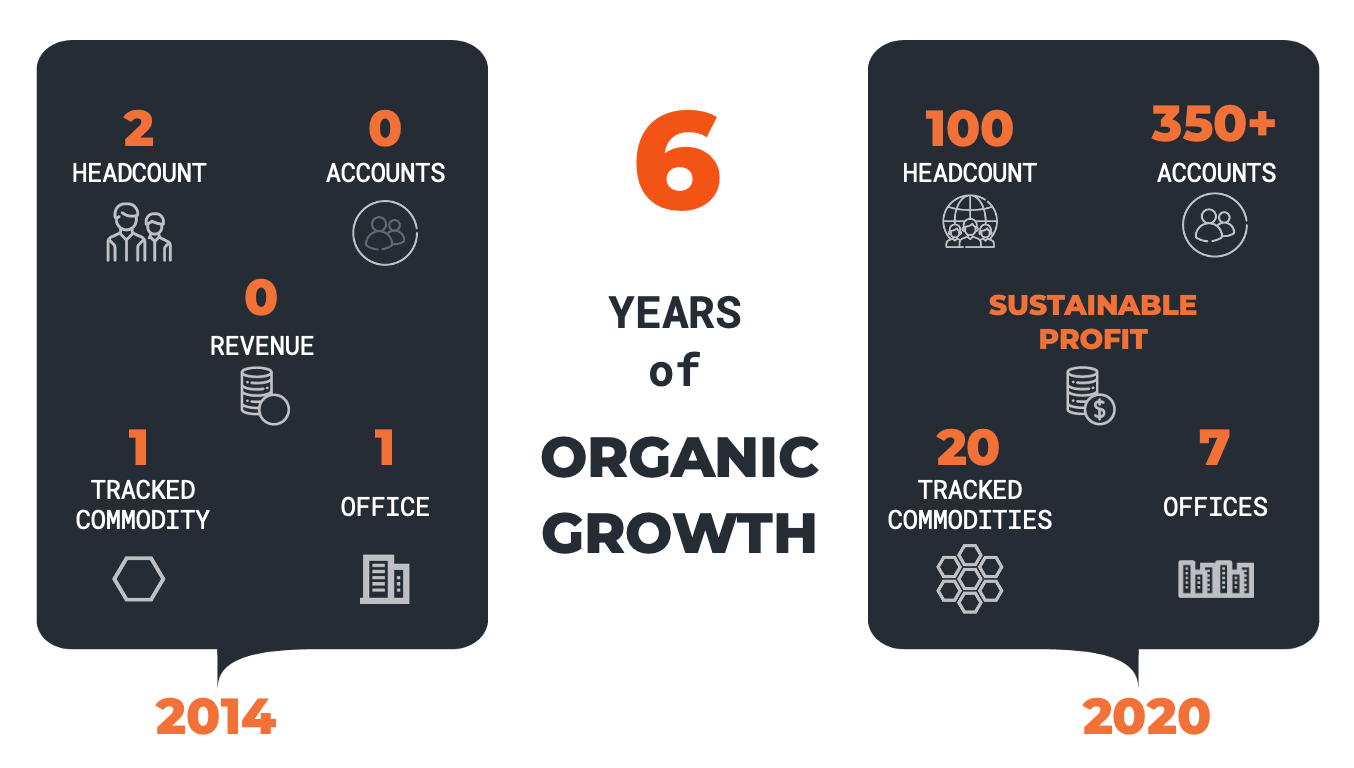
Kpler est désormais une entreprise internationale avec sept bureaux dans le monde – Houston, New York, Londres, Paris, Dubaï, Singapour, Tokyo – et plus de 100 employés. Kpler compte plus de 350 clients dans 65 pays qui sont principalement des grands comptes dans les domaines de l’énergie, l’industrie minière, l’industrie maritime, les trading houses, et les banques et hedge funds (fonds spéculatifs) qui sont sur les marchés de matières premières.
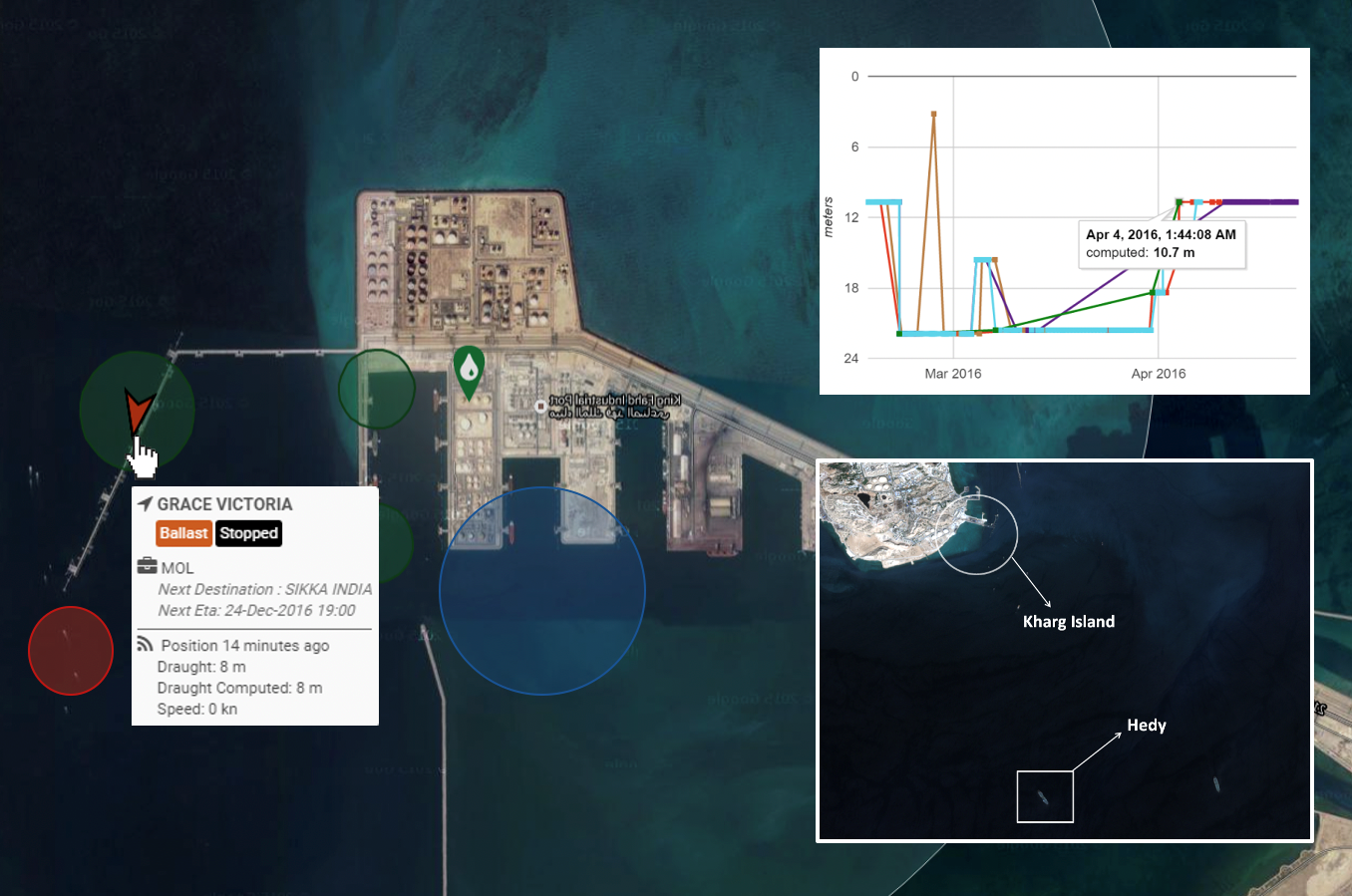
Kpler a créé un mapping très détaillé des installations impliquées dans le transport et le stockage des matières premières (terminaux portuaires, quais, pipelines, silos de stockage) avec beaucoup de métadonnées géographiques et temporelles.
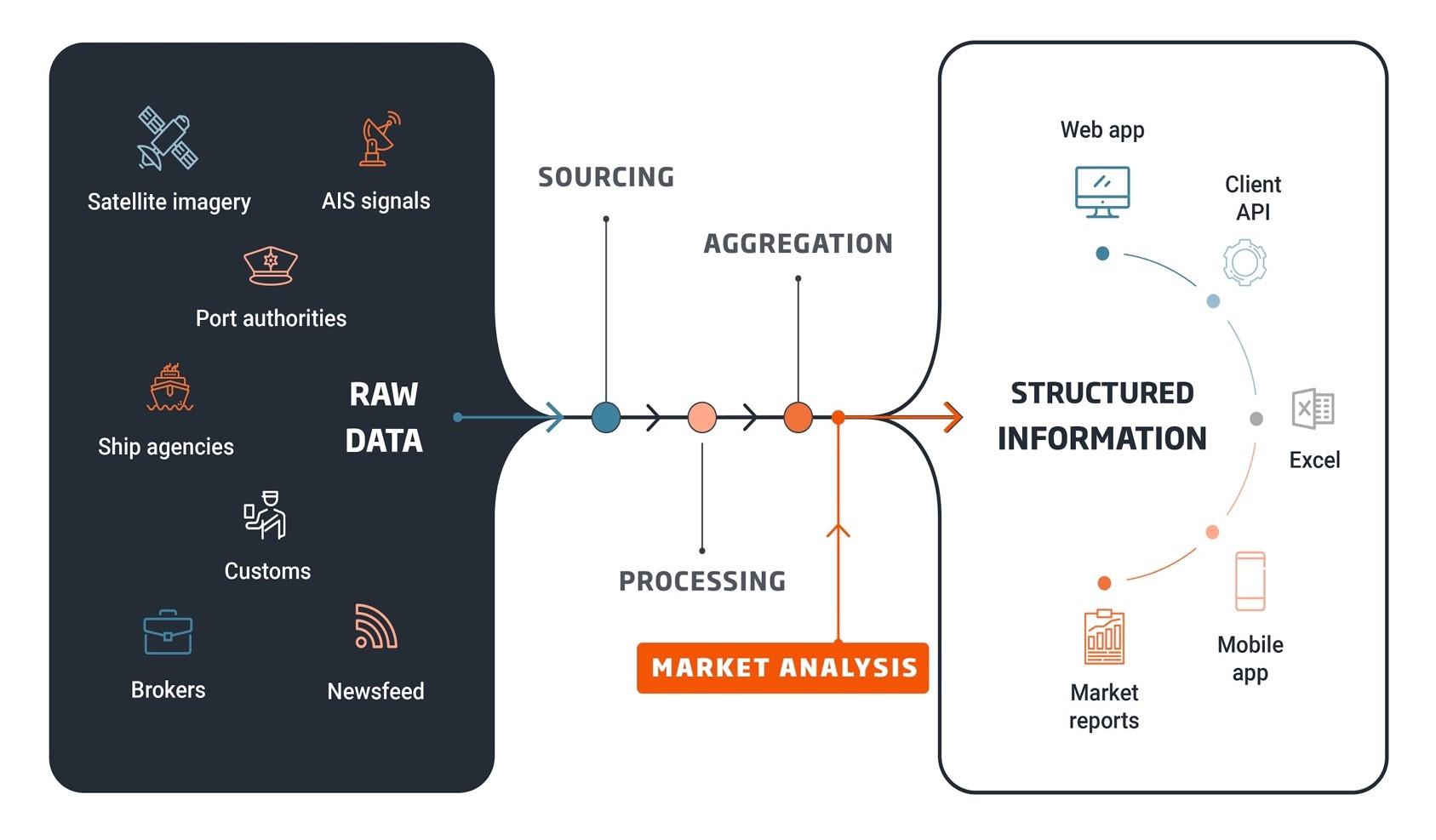
Le « pipeline data » de Kpler s’organise comme ceci :
- Sourcing et récupération de données brutes provenant de centaines de sources : signaux AIS (10 millions de signaux à traiter par jour sur le tracking de la position des navires), images satellites, rapports logistiques et commerciaux, rapport des autorités portuaires (scraping en temps réel de leurs sites web), rapports PDF des agences gouvernementales et maritimes, brokers, news feed (par exemple, post twitter d’un membre de l’équipage qui partage sa position), etc.
- Processing
- Agrégation : construction de métriques
- Market analysis : combinaison des données avec une expertise métier interne pour enrichir la qualité des données et s’assurer de la cohérence des résultats
- Information structurée fournie aux clients via de nombreux canaux : Web app (la plateforme compte plusieurs milliers d’utilisateurs), API client, tableaux Excel, App Mobile et rapports PDF.
Ne traitant pas des données de taille trop volumineuse (quelques centaines de Go par jour), Kpler n’utilise que très peu de technologies big data comme Spark. Le traitement se fait grâce à un ETL* sous Python et Scala, le stockage des données « froides » dans S3 et dans PostgreSQL pour les données géographiques et résultats des prédictions. Concernant la visualisation, le terminal Kpler (application web) utilise vuejs, mapbox et D3 pour avoir le maximum de performance.
* Extract, Transform and Load : logiciel capable de récupérer des données en provenance de plusieurs sources, de les convertir dans un format adapté à l’entrepôt de données et de les y transférer.
Cas d’usage : prévision de la congestion portuaire
Prévoir cette congestion est primordial pour Kpler afin que les données soient justes temporellement puisqu’un navire peut rester plusieurs jours à l’extérieur d’un port, ce qui engendre un décalage entre les prédictions de Kpler et la réalité. L’objectif est donc de savoir combien de temps un navire va attendre avant de pouvoir décharger ou charger sa marchandise en arrivant dans un port.
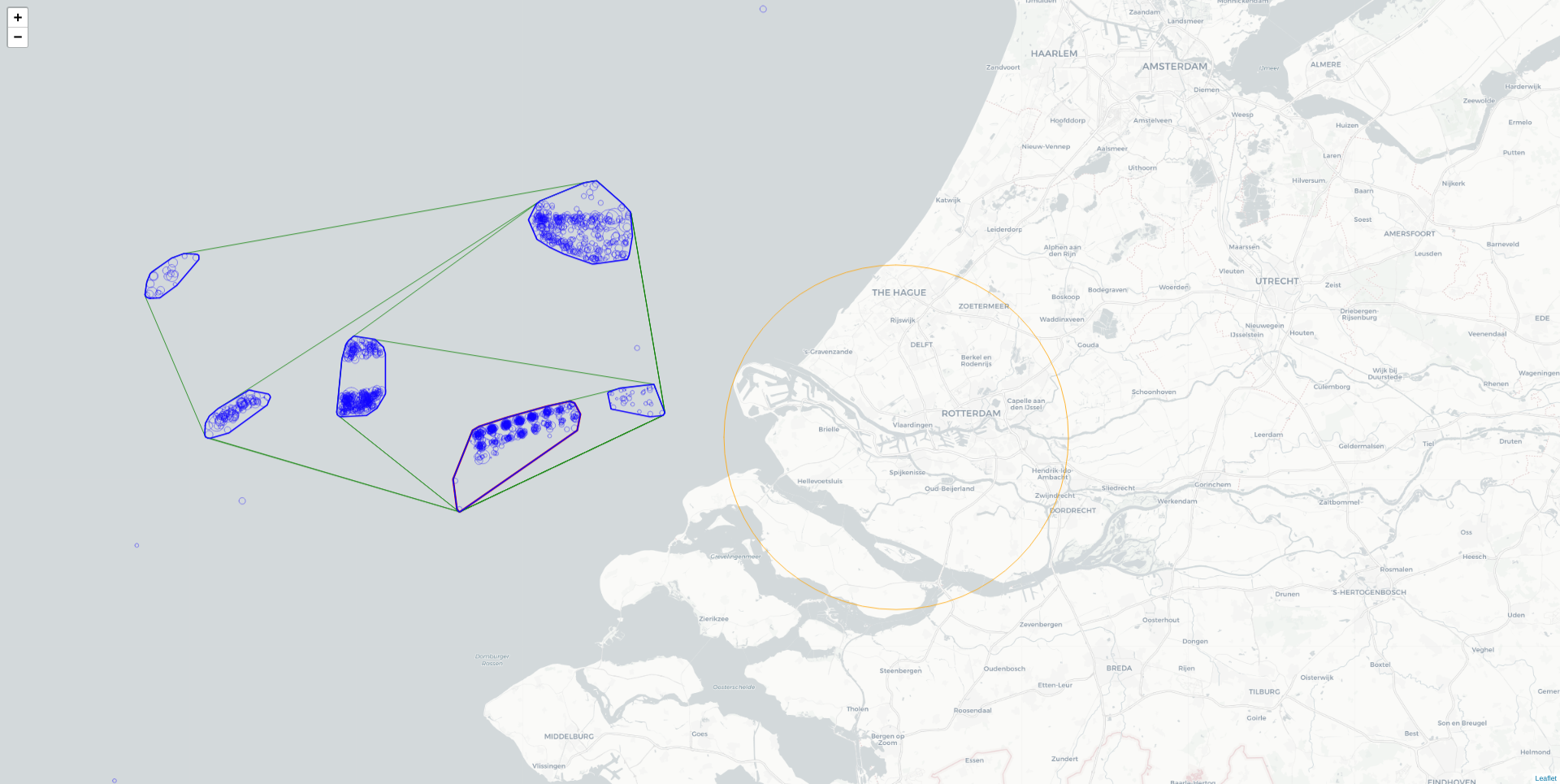
La première étape est la détermination d’un polygone représentant la zone d’attente de chaque port. Pour cela, la méthodologie utilisée est la suivante :
- Récupération de l’historique des appels navires-port
- Clustering des navires qui ont émis ces appels, qui ont une vitesse nulle et qui sont à proximité du port. L’algorithme utilisé pour le clustering est DBSCAN. L’idée est donc de créer des clusters sous forme de polygones représentant différentes zones d’attente
- Filtrage des polygones obtenus selon certaines règles (densité de navires, proximité du port…)
- Fusion des différents polygones jusqu’à atteindre un certain critère
Une fois la zone d’attente délimitée, la deuxième étape consiste à déterminer l’historique des temps d’attente d’un port, en récupérant l’historique des appels navires-port, puis en mesurant le temps d’arrivée dans la zone d’attente pour chaque appel.
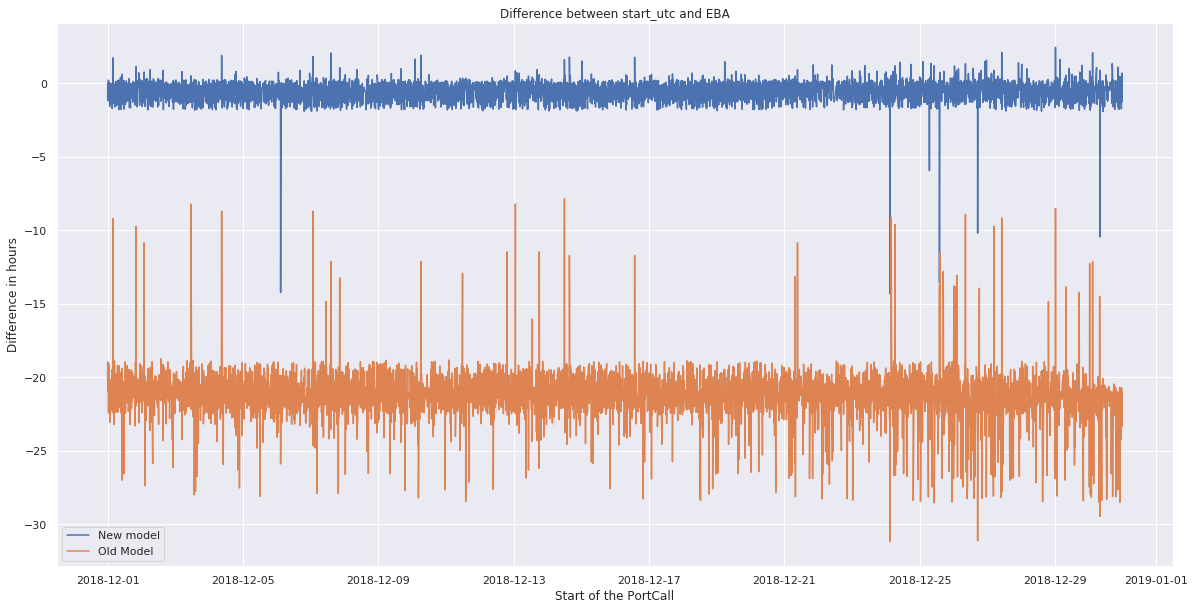
Enfin, la dernière étape est l’entraînement d’un modèle de prévision afin de prédire les durées de congestion. Moins d’une dizaine de paramètres sont utilisés pour cela : le type de navire, le jour de la semaine, le mois, le type de matière première, le type de transaction (import/export/autre), la position du navire dans la queue à son arrivée, le nombre de navires amarrés à l’arrivée du navire. Le modèle utilisé est un modèle de régression linéaire avec une régularisation Lasso, qui permet de garder l’interprétabilité, importante pour les clients.
Impacts du Covid-19 sur les imports/exports de gaz par pays
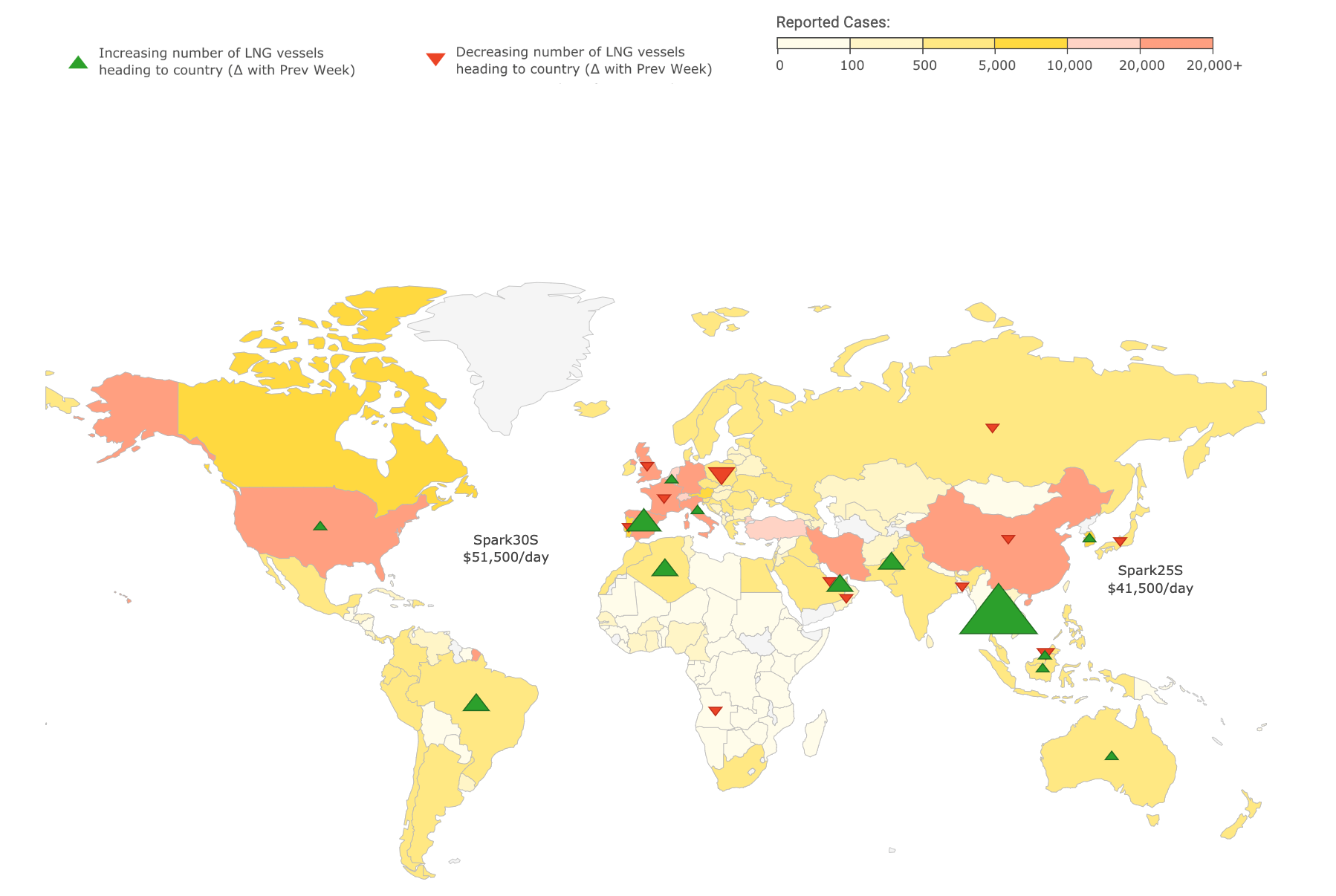
On pourrait penser que les pays qui comptent le plus de cas atteints par le Covid-19 sont ceux qui sont le plus touchés par les problèmes de congestion portuaire. C’était bien le cas, du moins pendant les premières semaines qui ont suivi l’apparition du virus.
Jean Maynier a présenté une carte du monde reflétant la variance des retards enregistrés et des différents problèmes de congestion dans différents ports dans le monde entre la semaine passée et la semaine en cours. Il s’avère qu’après une pénurie des matières premières, les pays les plus impactés par ces congestions ne sont pas nécessairement ceux les plus affectés par le Covid-19.
Compte-rendu rédigé par Sonia Bouden, Kevin Ferin et Jérémie Peres, étudiants de la promotion 2019-2020 du Mastère Spécialisé Big Data de Télécom Paris.