Trustii.io : une nouvelle plateforme de challenges big data
mercredi 9 décembre 2020
L’utilisation du machine learning (ML) comme outil de prédiction s’est fortement démocratisée au cours des dernières années, dans de nombreux domaines de l’industrie et pour des applications diverses (cybersécurité, maintenance prédictive, détection de fraudes…).
Pour une entreprise ayant à disposition des données qu’elle désire exploiter avec des modèles de machine learning (pour des tâches de classification, régression…), il existe 3 solutions principales pour créer des modèles :
- Les développer en interne, ce qui nécessite une expertise de la part de l’entreprise.
- Utiliser des plateformes compétitives comme Kaggle, mais cela implique de sélectionner un seul modèle parmi les candidats et ensuite de le déployer en interne.
- Utiliser des solutions d’auto-ML (modèles prédéfinis). Cependant, ils sont souvent de faible qualité et non adaptés aux besoins particuliers d’une entreprise.
Ainsi, Trustii propose une plateforme collaborative permettant aux entreprises, collectivités ou universités désirant exploiter leurs données, de générer des modèles. Cette plateforme SaaS se situe à l’intersection des trois solutions précédemment citées et son fonctionnement est simple. Elle propose d’abord un outil qui évalue si les données sont exploitables puis effectue une première modélisation afin d’avoir un aperçu de la prédiction renvoyée. Pour être évaluées, les données doivent être téléchargées sur la plateforme au format CSV, accompagnées d’une brève description du type de résultat désiré.
Au vu des résultats, l’organisation propriétaire des données peut décider d’améliorer la modélisation. Pour cela, elle peut rendre les données visibles et exploitables par les Data Scientists inscrits sur la plateforme, qui vont pouvoir apporter leur contribution en produisant leur propre modèle. Il est notamment possible pour chaque contributeur de comparer sa solution au modèle de base généré précédemment par la plateforme Trustii, afin d’évaluer ses performances.
Toutes les solutions proposées (Modèles Machine Learning) seront alors agrégées, grâce à des méthodes dites « d’Ensembling » pour produire un nouveau modèle optimal, qui sera à la fois plus performant que les modèles individuels mais aussi plus robuste au bruit. En effet, l’agrégation vise aussi à réduire la variance des résultats des modèles par souci de performance sur les données futures. La finalité de l’agrégation est donc d’avoir un bon compromis entre les scores, la parcimonie et la diversité des modèles proposés. La solution est alors récupérable et utilisable directement par l’organisateur du challenge.
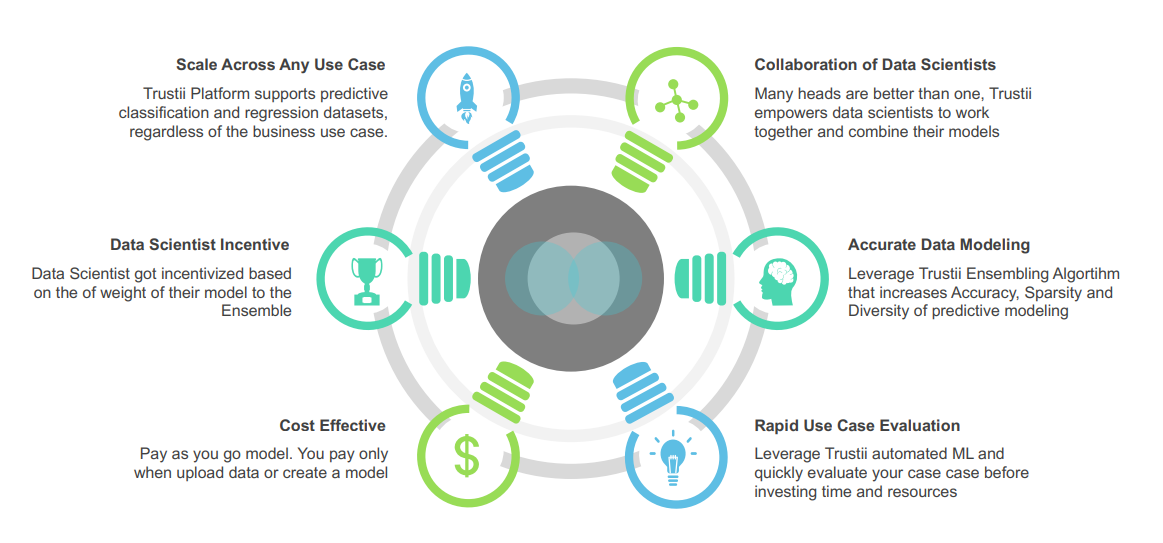
La grande différence de Trustii par rapport à des plateformes comme Kaggle est la prise en compte de chaque modèle candidat, selon sa pertinence et ses performances, pour répondre au problème. La rémunération des data scientists ayant contribué se fait également en fonction de l’importance qu’occupe leur modèle au sein du modèle final. La version Beta de la plateforme a été lancée il y a un mois, le 1er challenge public de la plateforme a déjà été lancé en collaboration avec l’Institut de Sciences des Données de Montpellier (ISDM).
Compte-rendu rédigé par Rémy Alline, Nicolas Favrot et Julien Muller, étudiants du Mastère Spécialisé Intelligence Artificielle promotion 2020-2021.
Illustration : photo créé par standret – fr.freepik.com