![]()
Lience : BSD License
Contributeurs : Albert Bifet et al.
Dernière mise à jour : mai 2020.
Scikit-multiflow s’inspire de MOA, la plateforme open source la plus populaire pour l’apprentissage statistique pour les flux de données, et de MEKA, une implémentation open source de méthodes pour l’apprentissage multi-label. Scikit-multiflow s’inspire également de scikit-learn, la bibliothèque Python la plus populaire pour l’apprentissage statistique.
Scikit-multiflow est implémenté en Python du fait de la popularité croissante de ce langage dans la communauté de l’apprentissage statistique. Il complète scikit-learn, dont l’objectif principal est l’apprentissage par lots, en élargissant l’ensemble des outils d’apprentissage automatique sur cette plateforme.
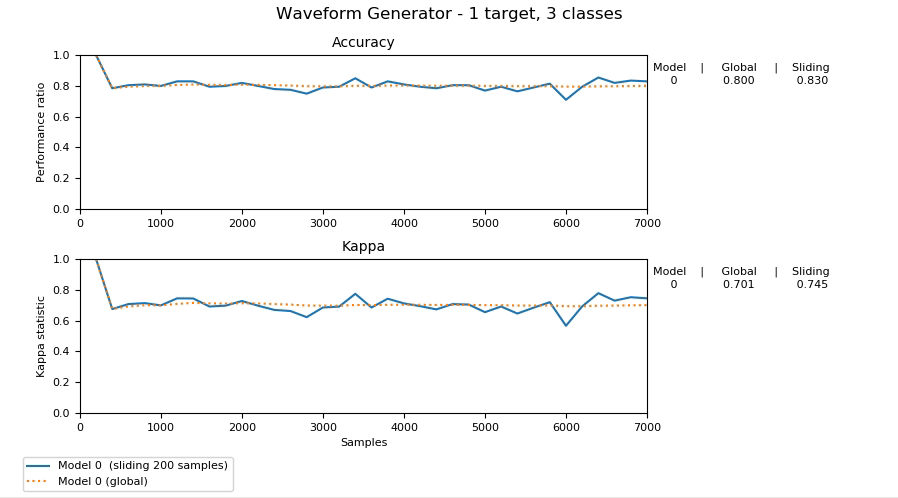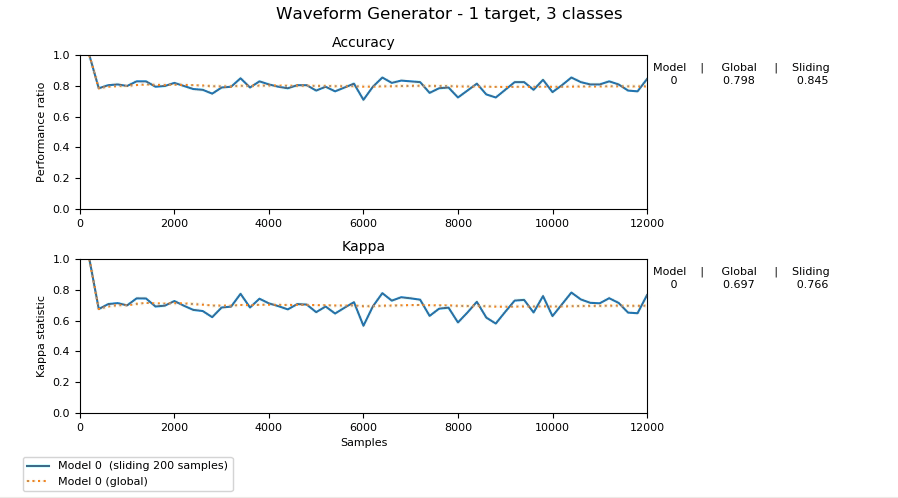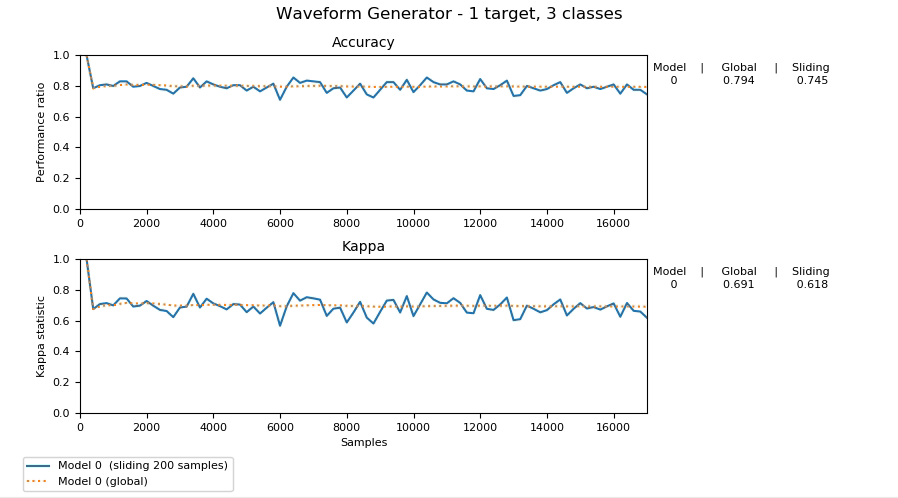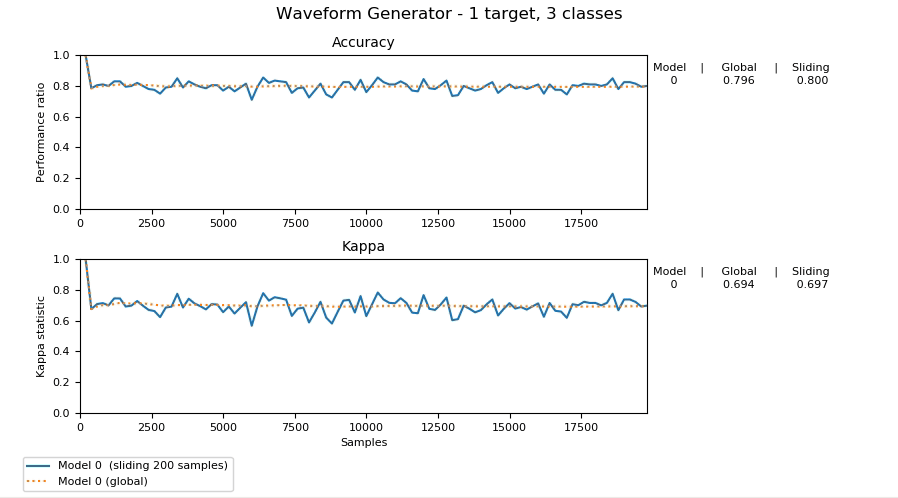
Dans son état actuel, scikit-multiflow contient des générateurs de flux, des méthodes d’apprentissage en flux pour des sorties et des cibles multiples, des détecteurs de changement et des méthodes d’évaluation.
Scikit-multiflow est développé par Télécom Paris, l’École polytechnique, l’Université de Waikato (Nouvelle-Zélande) et la communauté open source.